Clowder Fine-Tuning
In general, a base model may be fine-tuned in one of two ways:
- By changing the base model, which creates a new model, in which case it has no external layers but a different model.
- By adding EP layers, which retains the original base model, but provides additional layers that modify the model’s operation when loaded in memory to run.
This is a little like how to get a cherry cake. You can take a regular cake and put some cherries on top, or you can bake a cake with cherries in it. In both cases, you have a cake with cherries. However, one of them clearly is a cake layer and a cherry layer, while the other is a brand-new cake.
The end result is the same, but the way to get there is different.
From Clowder's perspective, if you have fine-tuned a model and redeployed it as a brand-new model, it is just yet another model. Clowder does not know or care that it originally was a base model that was fine-tuned. It is just a model, and it is treated as such.
The second option, where the base model is unchanged and EP layers are added, is more interesting. It allows for multiple fine-tunings of the same base model, and it allows for the base model to be reused in multiple different ways.
EP Layers are modifiers that are “layered” on top of a base model to modify, or fine-tune, it for runtime.
There are two main ways to use EP layers:
- When loading the model into memory, modify the model weights with the information in the EP layers. This looks in memory as if the original model had been modified.
- When loading the model into memory, load both the base model and the EP layers. With each inference, some of the model layers’ operations are modified to add additional steps after using the base model’s weights.
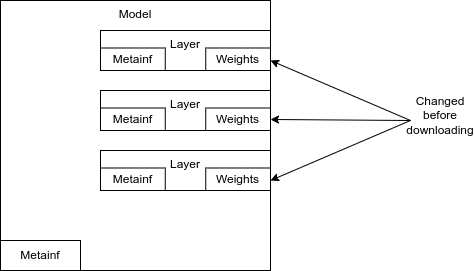
Scenario 1: Changed base model
Fine-tuning modifies the actual weights of the base model, leading to a new model.
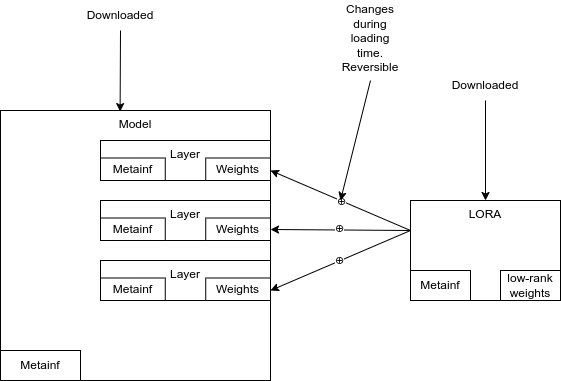
Scenario 2: Load-time modify weights
Fine-tuning generates an EP Layer. The base model is unchanged, and both the base model and EP Layer are stored separately. When loading the model into memory for inference, information in the EP Layer is used to modify the weights in memory in the base model.
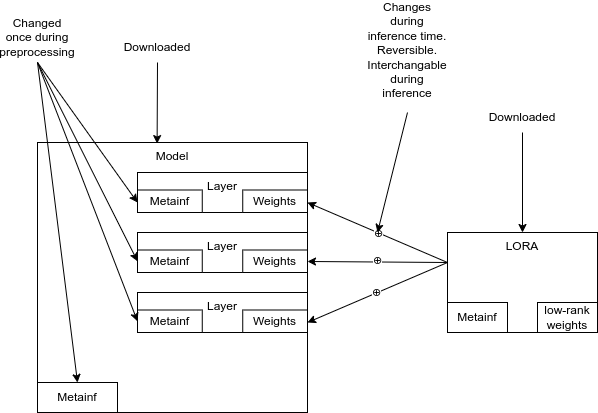
Scenario 3: Inference-time modify operations
Fine-tuning generates an EP Layer. The base model is unchanged, and both the base model and EP Layer are stored separately. When loading the model into memory for inference, the operations at affected layers are modified, such that after weights are applied, the output information is further modified by the EP Layer information, and then passed on to the next model layer.
The actual net result of inference in all three methods is the same. The effective differences are as follows:
| Feature | Changed Model | Load-Time Modify Weights | Inference-Time Modify Operations |
|---|---|---|---|
| Inference Results | Fine-tuned | Fine-tuned | Fine-tuned |
| Storage | Same as original model | Extra | Extra |
| Memory Usage | Same as original model | Same as original model | Extra |
| Processing Usage | Same as original model | Extra one-time cost on loading | Extra cost with each inference |
| Map to Original Model | No | Yes | Yes |
| Reusable Base Model Storage | No | Yes | Yes |
| Reusable Base Model GPU Memory | No | No | Possibly |
The runtime results of inference in all 3 scenarios is the same, but the storage, modifiability, and reusability differ.